如何将纸质材料转为word文档?
通过扫描仪将纸质材料扫描成图片格式。
首先安装扫描仪驱动,连接好扫描仪。 我用的是汉王OCR 6.0,打开软件后,先选择好相应的扫描仪,点击“扫描”。 模式我选的是“黑白图片”,经试验对于本来就比较清晰的文本这种格式的识别率最高,而且扫描速度也快。 对于不太清楚的文本可以使用自定义设置,多试验几个选项来加强识别率。 然后就要一页一页的将材料扫描为图片了,图片会自动保存到image目录下。
文字识别
点击“选择所有文字”,再点击“开始识别”,将保存的所有图片扫描为文本格式,这时会发现原来的图片文字会自动被识别保存到相应的文本文件里。 识别过程中发现对于某些情况汉王识别率可以迅速降为0,比如扫描文字右侧文字偏小时,有黑道时。这时可以借助另一款识别软件 清华紫光OCR 来进行识别。
文字修改
借助汉王强大的识别对照功能,可以轻松实现文字的修改。
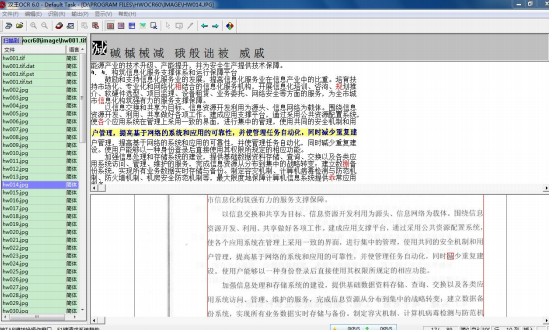
在上面的编辑区中,如果发现识别错误的地方,只需要将光标移过去,上方就会出现原来文字对照和文字提示,修改起来很方便。美中不足之处就是不能用鼠标滚轮移动页面,需要借助键盘上的上下箭头。另外“施”这个字无法修改,不知道什么原因….修改好一页后,只需要在左侧导航栏里点击下一幅图片就可以了,系统会自动保存。也幸亏有这个功能,汉王一高兴了就死掉,不知道为何原因。。。
文件整理到word中
编程实现各文本文件汇总到一个单一文件中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
在word中将全部空格,回车符替换为空,然后分段,然后整体修改,搜索“设旋”、“设旌”改为“设施”… 完善格式…
ps
Microsoft Office 工具里的Microsoft Office Document Imaging也可以实现识别功能,看它的版权页发现使用的是清华紫光的TH-OCR技术,不过是2002版本的,比起网上下载的99版TH-OCR好多了。可以考虑应用VBA做一些批处理操作。
另外下载了据称是世界上最先进的识别软件ABBYY FineReader,试用版可以使用15天,识别50页,试用了下效果还可以。注册的话需要$200。